个人简介
顾彬,BETVLCTOR伟德官方网站准聘教授,博士生导师。研究兴趣集中在利用优化技术实现大规模机器学习问题的求解以及下一代神经网络(即脉冲神经网络)的研究与应用,具体包括如下的一些子问题:
-脉冲神经网络
-大规模超参优化
-联邦学习
-黑盒优化
-强化学习
教育背景
于2001年至2010年在南京航空航天大学计算机科学与技术学院学习,期间获得学士及博士学位。
工作经历
于2011年至2024年在南京信息工程大学任教,并于2018年升至教授。期间在加拿大西安大略大学、美国得克萨斯州立大学阿灵顿分校、匹兹堡大学、京东科技集团、阿联酋穆罕默德-本-扎耶德人工智能大学从事科学研究工作。
论文发表
[131]H. Xiong, L. Huang, W. J. Zang, X. Zhen, G.-S. Xie, Bin Gu, and L. Song. On the number of linear regions of convolutional neural networks with piecewise linear activations, IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 01, pp. 1-18, 2024.
[130]Chenkang Zhang, Heng Huang, and Bin Gu. Tackle balancing constraints in semi-supervised ordinal regression. Machine Learning, (accepted)
[129]Ganyu Wang, Qingsong Zhang, Xiang Li, Boyu Wang, Bin Gu, Charles X. Ling. Secure and fast asynchronous vertical federated learning via cascaded hybrid optimization, Machine Learning, (accepted)
[128]Yajing Fan, Shuyang Yu, Bin Gu, Ziran Xiong, Zhou Zhai, Heng Huang, and Yi Chang. Global Model Selection for Semi-Supervised Support Vector Machine via Solution Paths. IEEE Transactions on Neural Networks and Learning Systems. (accepted)
[127]Zhuang Qian, Shufei Zhang, Kaizhu Huang, Qiufeng Wang, Xinping Yi, Bin Gu, Huan Xiong. Perturbation diversity certificates robust generalization. Neural Networks. (accepted)
[126]Srinivas Anumasa, Velibor Bojkovic, Giulia De Masi, Bin Gu, Huan Xiong. Data Driven Threshold and Potential Initialization for Ultra-low Latency Performance of Spiking Neural Networks. AISTATS 2024. (accepted)
[125]Zhou Zhai, Wanli Shi, Heng Huang, Yi Chang, Bin Gu. Learning Sampling Policy to Achieve Fewer Queries for Zeroth-Order Optimization. AISTATS 2024. (accepted)
[124]Yajing Fan, Wanli Shi, Yi Chang, Bin Gu. Fast and Adversarial Robust Kernelized SDU Learning. AISTATS 2024. (accepted)
[123]Xinzhe Yuan, William de Vazelhes, Bin Gu, Huan Xiong. New Insight of Variance Reduce in Zero-Order Hard-Thresholding: Mitigating Gradient Error and Expansivity Contradictions. ICLR 2024. (accepted)
[122]Longkang Li, Ignavier Ng, Gongxu Luo, Biwei Huang, Guangyi Chen, Tongliang Liu, Bin Gu, Kun Zhang. Federated Causal Discovery from Heterogeneous Data. ICLR 2024. (accepted)
[121]Nan Yin, Mengzhu Wang, Zhenghan Chen, Li Shen, Huan Xiong, Bin Gu, Xiao Luo. DREAM: Dual Structured Exploration with Mixup for Open-set Graph Domain Adaption. ICLR 2024. (accepted)
[120]Bhaskar Mukhoty, Hilal AlQuabeh, Giulia De Masi, Huan Xiong, Bin Gu. Certified Adversarial Robustness for Rate Encoded Spiking Neural Networks. ICLR 2024. (accepted)
[119]Haiyan Jiang, Vincent Zoonekynd, Giulia De Masi, Bin Gu, Huan Xiong. TAB: Temporal Accumulated Batch Normalization in Spiking Neural Networks. ICLR 2024. (accepted)
[118]Xinyue Liu, Hualin Zhang, Bin Gu, Hong Chen. General Stability Analysis for Zeroth-Order Optimization Algorithms. ICLR 2024. (accepted)
[117]Diyang Li, Charles Ling, Zhiqiang Xu, Huan Xiong, Bin Gu. Learning No-Regret Sparse Generalized Linear Models with Varying Observation(s). ICLR 2024. (spotlight)
[116]Hilal Mohammad Hilal AlQuabeh, William de Vazelhes, Bin Gu. Limited Memory Online Gradient Descent for Kernelized Pairwise Learning with Dynamic Averaging. AAAI 2024. (accepted)
[115] William de Vazelhes, Bhaskar Mukhoty, Xiaotong Yuan, Bin Gu. Iterative Regularization with k-Support Norm: an Important Complement to Sparse Recovery. AAAI 2024. (accepted)
[114]Nan Yin, Mengzhu Wang, Giulia De Masi, Bin Gu, Huan Xiong. Dynamic Spiking Graph Neural Networks. AAAI 2024. (accepted)
[113]Srinivas Anumasa, Bhaskar Mukhoty, Velibor Bojkovic, Giulia De Masi, Huan Xiong, Bin Gu. Enhancing Training of Spiking Neural Network with Stochastic Latency. AAAI 2024. (accepted)
[112]Zhou Zhai, Bin Gu, Cheng Deng and Heng Huang. Global Model Selection via Solution Paths for Robust Support Vector Machine. IEEE Transactions on Pattern Analysis and Machine Intelligence. (accepted)
[111]Nan Yin, Li Shen, Huan Xiong, Bin Gu, Chong Chen, Xian-Sheng Hua, Siwei Liu, Xiao Luo. Messages Are Never Propagated Alone: Collaborative Hypergraph Neural Network for Time-series Forecasting. IEEE Transactions on Pattern Analysis and Machine Intelligence. (accepted)
[110]Bin Gu, Xiyuan Wei, Hualin Zhang, Yi Chang, Heng Huang. Obtaining Lower Query Complexities through Lightweight Zeroth-Order Proximal Gradient Algorithms. Neural Computation. (accepted)
[109]Yufan Huang, Mengnan Qi, Yongqiang Yao, Maoquan Wang, Bin Gu, Colin Clement, Neel Sundaresan. Program Translation via Code Distillation. EMNLP 2023. (to appear)
[108]Mengnan Qi, Yufan Huang, Maoquan Wang, Yongqiang Yao, Zihan Liu, Bin Gu, Colin Clement, Neel Sundaresan. SUT: Active Defects Probing for Transcompiler Models. EMNLP 2023. (to appear)
[107]Xiaohan Zhao, Hualin Zhang, Zhouyuan Huo, Bin Gu*. Accelerated On-Device Forward Neural Network Training with Module-Wise Descending Asynchronism. NeurIPS 2023. (accepted)
[106]Jun Chen, Hong Chen, Bin Gu, Hao Deng. Fine-Grained Theoretical Analysis of Federated Zeroth-Order Optimization. NeurIPS 2023. (accepted)
[105]Ganyu Wang, Bin Gu*, Qingsong Zhang, Xiang Li, Boyu Wang, Charles X. Ling*. A Unified Solution for Privacy and Communication Efficiency in Vertical Federated Learning. NeurIPS 2023. (accepted)
[104]Bhaskar Mukhoty, Velibor Bojkovic, William de Vazelhes, Xiaohan Zhao, Giulia De Masi, Huan Xiong*, Bin Gu*. Variance Reduced Online Gradient Descent for Kernelized Pairwise Learning with Limited Memory. NeurIPS 2023. (accepted)
[103]Bin Gu, Runxue Bao, Chenkang Zhang, Heng Huang. New Scalable and Efficient Online Pairwise Learning Algorithm. IEEE Transactions on Neural Networks and Learning Systems. (accepted)
[102]Hilal Mohammad Hilal AlQuabe'h, Bhaskar Mukhoty, Bin Gu*. Variance Reduced Online Gradient Descent for Kernelized Pairwise Learning with Limited Memory. ACML 2023. (accepted)
[101]Huimin Wu, Wanli Shi, Zhang Chenkang, Bin Gu*. Self-Adaptive Perturbation Radii for Adversarial Training. KDD 2023.
[100]Zhang Chenkang, Wanli Shi, Lei Luo, Bin Gu*. Doubly Robust AUC Optimization against Noisy and Adversarial Samples. KDD 2023.
[99]Haiyan Jiang, Srinivas Anumasa, Giulia De Masi, Huan Xiong, Bin Gu*. A unified optimization framework of ANN-SNN Conversion: towards optimal mapping from activation values to firing rates. ICML 2023.
[98]Bin Gu, Zhouyuan Huo, Chenkang Zhang, Cheng Deng, Heng Huang. A New Large-Scale Learning Algorithm for Generalized Additive Models. Machine Learning.
[97]Hualin Zhang, Bin Gu*. Faster Gradient-Free Methods for Escaping Saddle Points. ICLR 2023.
[96]Hongchang Gao, Bin Gu, My T Thai. Stochastic bilevel distributed optimization over a network. AISTATS 2023.
[95]Zhou Zhai, Lei Luo, Heng Huang, Bin Gu*. Faster Fair Machine via Transferring Fairness Constraints to Virtual Samples. AAAI 2023.
[94]Chenkang Zhang, Lei Luo, Bin Gu*. Denoising Multi-Similarity Formulation: A Self-paced Curriculum-Driven Approach for Robust Metric Learning. AAAI 2023.
[93]Diyang Li, Bin Gu*. When Online Learning Meets ODE: Learning without Forgetting on Variable Feature Space. AAAI 2023.
[92]Jun Chen, Hong Chen, XUE JIANG, Bin Gu, Weifu Li, Tieliang Gong, Feng Zheng. On the Stability and Generalization of Triplet Learning. AAAI 2023.
[91]Jiahuan Wang, Jun Chen, Hong Chen, Bin Gu, Weifu Li, Xin Tang. Hong Chen, Bin Gu. Stability-based Generalization Analysis for Mixtures of Pointwise and Pairwise Learning. AAAI 2023.
[90]Hualin Zhang, Huan Xiong, Bin Gu*. Zeroth-Order Negative Curvature Finding: Escaping Saddle Points without Gradients. NeurIPS 2022.
[89] Xingyu Qu, Diyang Li, Xiaohan Zhao, Bin Gu*. GAGA: Deciphering Age-path of Generalized Self-paced Regularizer. NeurIPS 2022.
[88]William de Vazelhes, Hualin Zhang, Huimin Wu, Xiaotong Yuan, Bin Gu*. Zeroth-Order Hard-Thresholding: Gradient Error vs. Expansivity. NeurIPS 2022.
[87]Huimin Wu, William de Vazelhes, Bin Gu*. Efficient Semi-Supervised Adversarial Training without Guessing Labels. ICDM 2022.
[86]Zhiyuan Dang, Bin Gu, Cheng Deng, Heng Huang. Asynchronous Parallel Large-Scale Gaussian Process Regression. IEEE Transactions on Neural Networks and Learning Systems.
[85]Runxue Bao, Bin Gu, Heng Huang. An Accelerated Doubly Stochastic Gradient Method with Faster Explicit Model Identification. CIKM 2022.
[84]Zhengqing Gao, Huimin Wu, Martin Takac and Bin Gu*. Towards Practical Large Scale Non-Linear Semi-Supervised Learning with Balanced Constraints. CIKM 2022.
[83]Bin Gu, Zhou Zhai, Xiang Li, Heng Huang. Towards Fairer Classifier via True Fairness Score Path. CIKM 2022.
[82] Haiyan Chen, Yin Yu, Yizhen Jia, Bin Gu*. Incremental Learning for Transductive Support Vector Machine. Pattern Recognition.
[81]Zhou Zhai, Heng Huang, Bin Gu*. Kernel Path for Semi-Supervised Support Vector Machine. IEEE Transactions on Neural Networks and Learning Systems.
[80]Wanli Shi, Hongchan Gao, Bin Gu*. Gradient-Free Method for Heavily Constrained Nonconvex Optimization. ICML 2022.
[79]Alexander Gasnikov, Anton Novitskii, Vasilii Novitskii, Farshed Abdukhakimov, Dmitry Kamzolov, Aleksandr Beznosikov, Martin Takáč, Pavel Dvurechensky, Bin Gu. The power of first-order smooth optimization for black-box non-smooth problems. ICML 2022.
[78]Ziran Xiong, Wanli Shi, Bin Gu*. End-to-End Semi-Supervised Ordinal Regression AUC Maximization with Convolutional Kernel Networks. KDD 2022.
[77]Ziran Xiong, Charles X. Ling, Bin Gu*. Kernel Error Path Algorithm. IEEE Transactions on Neural Networks and Learning Systems.
[76]Haiyan Chen, Yizhen Jia, Jiaming Ge, Bin Gu*. Incremental learning algorithm for large-scale semi-supervised ordinal regression. Neural Networks.
[75]Bin Gu, Chenkang Zhang, Huan Xiong, Heng Huang. Balanced Self-Paced Learning for AUC Maximization. AAAI 2022.
[74]Junyi Li, Bin Gu, Heng Huang. A Fully Single Loop Algorithm for Bilevel Optimization without Hessian Inverse. AAAI 2022.
[73]Diyang Li, Bin Gu*. Chunk Dynamic Updating for Group Lasso with ODEs. AAAI 2022.
[72]Bin Gu, Zhou Zhai, Xiang Li, Heng Huang. Finding Age Path of Self-Paced Learning. ICDM 2021.
[71]Qinsong Zhang, Bin Gu, Cheng Deng, Heng Huang. Desirable Companion for Vertical Federated Learning: New Zeroth-Order Gradient Based Algorithm. CIKM 2021.
[70]Qinsong Zhang, Bin Gu, Cheng Deng, Jian Pei, Heng Huang. AsySQN: Faster Vertical Federated Learning Algorithms with Better Computation Resource Utilization. KDD 2021.
[69]Bin Gu, Ziran Xiong, Xiang Li, Zhou Zhai, Guansheng Zheng. Kernel Path for 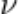 -Support Vector Classification. IEEE Transactions on Neural Networks and Learning Systems.
-Support Vector Classification. IEEE Transactions on Neural Networks and Learning Systems.
[68]Bin Gu, Xiyuan Wei, Shangqian Gao, Ziran Xiong, Cheng Deng and Heng Huang. Back-Box Reductions for Zeroth-Order Gradient Algorithms to Achieve Lower Query Complexity. Journal of Machine Learning Research (JMLR).
[67]Bin Gu, Charles X. Ling. Generalized Error Path Algorithm. Pattern Recognition.
[66]Wanli Shi, Bin Gu, Xiang Li, Cheng Deng and Heng Huang. Triply Stochastic Gradient Method for Large-Scale Nonlinear Similar Unlabeled Classification. Machine Learning.
[65]Bin Gu, Ziran Xiong, Shuyang Yu, Guansheng Zheng. A Kernel Path Algorithm for General Parametric Quadratic Programming Problem. Pattern Recognition.
[64]Bin Gu, An Xu, Zhouyuan Huo, Cheng Deng and Heng Huang. Privacy-Preserving Asynchronous Vertical Federated Learning Algorithms for Multi-Party Collaborative Learning. IEEE Transactions on Neural Networks and Learning Systems.
[63]Zhiyuan Dang, Bin Gu, Heng Huang. Large-Scale Kernel Method for Vertical Federated Learning. Federated Learning. Springer.
[62]Bin Gu, Zhiyuan Dang, Zhouyuan Huo, Cheng Deng and Heng Huang. Scaling Up Generalized Kernel Methods. IEEE Transactions on Pattern Analysis and Machine Intelligence.
[61]Wanli Shi, Bin Gu, Heng Huang. Improved Penalty Method via Doubly Stochastic Gradients for Bilevel Hyperparameter Optimization. AAAI 2021.
[60]Zhouyuan Huo, Bin Gu, Heng Huang. Large Batch Optimization for Deep Learning Using New Complete Layer-Wise Adaptive Rate Scaling. AAAI 2021.
[59]Huimin Wu, Bin Gu, Zhengmian Hu, Heng Huang. Fast and Scalable Adversarial Training of Kernel SVM via Doubly Stochastic Gradients. AAAI 2021.
[58]Qinsong Zhang, Bin Gu, Cheng Deng, Heng Huang. Secure Bilevel Asynchronous Vertical Federated Learning with Backward Updating. AAAI 2021.
[57]Zhiyuan Dang, Xiang Li, Bin Gu, Cheng Deng, Heng Huang. Large Scale Nonlinear AUC Maximization via Triply Stochastic Gradients. IEEE Transactions on Pattern Analysis and Machine Intelligence.
[56]Bin Gu, Wenhan Xian, Zhouyuan Huo, Cheng Deng and Heng Huang. A Unified q-Memorization Framework for Asynchronous Stochastic Optimization. JMLR.
[55]Bin Gu, Zhou Zhai, Cheng Deng, and Heng Huang. Efficient Active Learning by Querying Discriminative and Representative Samples and Fully Exploiting Unlabeled Data. IEEE Transactions on Neural Networks and Learning Systems.
[54]Bin Gu, Xiang Geng, Xiang Li, Wanli Shi, Guansheng Zheng, Cheng Deng, and Heng Huang. Scalable Kernel Ordinal Regression via Doubly Stochastic Gradients. IEEE Transactions on Neural Networks and Learning Systems.
[53]Bin Gu, Xiang Geng, Wanli Shia, Yingying Shana, Yufang Huang, Zhijie Wang, Guansheng Zheng. Solving Large-Scale Support Vector Ordinal Regression with Asynchronous Parallel Coordinate Descent Algorithms. Pattern Recognition.
[52]Runxue Bao, Bin Gu, Heng Huang. Fast OSCAR and OWL with Safe Screening Rules. ICML 2020.
[51]Bin Gu, Zhiyuan Dang, Xiang Li and Heng Huang. Federated Doubly Stochastic Kernel Learning for Vertically Partitioned Data. KDD 2020.
[50]Wanli Shi,Victor S. Sheng, Xiang Li, Bin Gu*. Semi-Supervised Multi-Label Learning from Crowds via Deep Sequential Generative Model. KDD 2020.
[49]Wanli Shi, Bin Gu, Xiang Li, Heng Huang. Quadruply Stochastic Gradient Method for Large Scale Nonlinear Semi-Supervised Ordinal Regression AUC Optimization. AAAI 2020.
[48]Zhou Zhai, Bin Gu, Xiang Li, Heng Huang. Safe Sample Screening for Robust Support Vector Machine. AAAI 2020.
[47]Runxue Bao, Bin Gu, Heng Huang. Efficient Approximate Solution Path Algorithm for Order Weight L_1-Norm with Accuracy Guarantee. ICDM 2019.
[46]Bin Gu, Xiang Geng, Xiang Li, Guansheng Zheng. Efficient Inexact Proximal Gradient Algorithms for Structured Sparsity-Inducing Norm. Neural Networks.118 (2019): 352-362.
[45]Bin Gu, Wenhan Xian, Heng Huang. Asynchronous Stochastic Frank-Wolfe Algorithms for Non-convex Optimization. IJCAI 2019.
[44]Xiang Geng, Bin Gu, Xiang Li, Wanli Shi, Guansheng Zheng, Heng Huang. Scalable Semi-Supervised SVM via Triply Stochastic Gradients. IJCAI 2019.
[43]Wanli Shi, Bin Gu, Xiang Li, Xiang Geng, Heng Huang. Quadruply Stochastic Gradients for Large-Scale Nonlinear Semi-Supervised AUC Optimization. IJCAI 2019.
[42]Shuyang Yu, Bin Gu, Kunpeng Ning, Haiyan Chen, Jian Pei and Heng Huang. Tackle Balancing Constraint for Incremental Semi-Supervised Support Vector Learning. KDD 2019.
[41]Bin Gu, Yingying Shan,Xin Quan, Guansheng Zheng. Accelerating Sequential Minimal Optimization via Stochastic Sub-Gradient Descent. IEEE Transactions on Cybernetics. DOI: 10.1109/TCYB.2019.
[40]Feihu Huang, Bin Gu, Zhouyuan Huo, Songcan Chen, Heng Huang. Faster Gradient-Free Proximal Stochastic Methods for Nonconvex Nonsmooth Optimization. AAAI 2019.
[39]Bin Gu, Zhouyuan Huo, Heng Huang. Scalable and Efficient Pairwise Learning to Achieve Statistical Accuracy. AAAI 2019.
[38]Zhouyuan Huo, Bin Gu, Heng Huang. Training Neural Networks Using Features Replay. NIPS 2018.
[37]Bin Gu, Xin Quan, Yunhua Gu, Victor S. Sheng, Guansheng Zheng. Chunk Incremental Learning for Cost-Sensitive Hinge Loss Support Vector Machine. Pattern Recognition.
[36]Bin Gu, Zhouyuan Huo, Heng Huang. Faster Derivative-Free Stochastic Algorithm for Shared Memory Machines. ICML 2018.
[35]Zhouyuan Huo, Bin Gu, Qian Yang, Heng Huang. Decoupled Parallel Backpropagation with Convergence Guarantee. ICML 2018.
[34]Bin Gu, Xiao-Tong Yuan, Songcan Chen, Heng Huang. New Incremental Learning Algorithm for Semi-Supervised Support Vector Machine. KDD 2018.
[33] Bin Gu, Yinyin Shan, Xiang Geng, Guansheng Zheng, Heng Huang. Accelerated Asynchronous Greedy Coordinate Descent Algorithm for SVMs. IJCAI 2018 .
[32] Bin Gu, Xinwang Ju, Xiang Li, Guansheng Zheng, Heng Huang. Faster Training Algorithms for Structured Sparsity-Inducing Norm. IJCAI 2018 .
[31] Bin Gu, Zhouyuan Huo, Heng Huang. Asynchronous Doubly Stochastic Group Regularized Learning. International Conference on Artificial Intelligence and Statistics. 2018. p. 1791-1800.
[30]Bin Gu, Victor S. Sheng. A Solution Path Algorithm for General Parametric Quadratic Programming Problem. IEEE Transactions on Neural Networks and Learning Systems.
[29]Bin Gu. A Regularization Path Algorithm for Support Vector Ordinal Regression. Neural Networks, 98 (2018): 114-121.
[28]Xiang Li, Huaimin Wang, Bin Gu, Charles X Ling. The convergence of linear classifiers on large sparse data. Neurocomputing, 2018, 273: 622-633.
[27]Bin Gu, De Wang, Zhouyuan Huo, Heng Huang. Inexact Proximal Gradient Methods for Non-convex and Non-smooth Optimization.AAAI 2018.
[26]Zhouyuan Huo, Bin Gu, Heng Huang. Accelerated Method for Stochastic Composition Optimization with Nonsmooth Regularization, AAAI 2018
[25]Bin Gu, Xin Miao, Zhouyuan Huo, Heng Huang. Asynchronous Doubly Stochastic Sparse Kernel Learning, AAAI 2018
[24]Bin Gu, Guodong Liu, Heng Huang. Groups-Keeping Solution Path Algorithm for Sparse Regression with Automatic Feature Grouping. KDD 2017. 2017. p. 185-193. (Oral Presentation)
[23]Xiang Li, Bin Gu, Shuang Ao, Huaiming Wang, Charles X. Ling. Triply Stochastic Gradients on Multiple Kernel Learning, UAI 2017
[22]Victor Sheng, Jing Zhang, Bin Gu, Xindong Wu. Majority Voting and Pairing with Multiple Noisy Labeling. IEEE Transactions on Knowledge and Data Engineering. 2017.
[21]Bin Gu, Victor S. Sheng, Keng Yeow Tay, Walter Romano, and Shuo Li. Cross Validation Through Two-dimensional Solution Surface for Cost-Sensitive SVM. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2017, 39.6: 1103-1121.
[20]Bin Gu, Xinming Su, Victor S. Sheng. Structural Minimax Probability Machine. IEEE Transactions on Neural Networks and Learning Systems. 2017, 28.7: 1646-1656.
[19]Bin Gu, Victor S. Sheng. A Robust Regularization Path Algorithm for ν-Support Vector Classification. IEEE Transactions on Neural Networks and Learning Systems. 2017, 28.5: 1241-1248.
[18]Bin Gu, Yingying Shan, Victor S. Sheng, and Shuo Li. Sparse Regression with Output Correlation for Cardiac Ejection Fraction Estimation. Information Sciences. 2018, 423: 303-312.
[17]Bin Gu, and Charles Ling. "A New Generalized Error Path Algorithm for Model Selection." Proceedings of the 32nd International Conference on Machine Learning (ICML-15). 2015.
[16]Bin Gu, Victor S. Sheng, and Shuo Li. Bi-parameter space partition for cost-sensitive SVM. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25-31, 2015, pages 3532–3539, 2015.
[15]Xiang Li, Huaiming Wang, Bin Gu, Charles X. Ling. Data Sparseness in Linear SVM. IJCAI 2015:3628-3634.
[14]Bin Gu, Victor S. Sheng, Keng Yeow Tay, Walter Romano, and Shuo Li. Incremental Learning for ν-Support Vector Regression. Neural Networks. 67 (2015): 140-150.
[13]Bin Gu, Victor S. Sheng, Keng Yeow Tay, Walter Romano, and Shuo Li. Incremental Support Vector Learning for Ordinal Regression. IEEE Transactions on Neural Networks and Learning Systems, 26(7), pp. 1403 - 1416, 2015.
[12]Wang, Z.; Salah, M.B.; Gu, B.; Islam, A.; Goela, A.; Li, S., "Direct Estimation of Cardiac Biventricular Volumes With an Adapted Bayesian Formulation," Biomedical Engineering, IEEE Transactions on , vol.61, no.4, pp.1251-1260, 2014.
[11]Victor S. Sheng, Bin Gu, Wei Fang, Jian Wu, Cost-sensitive learning for defect escalation, Knowledge-Based Systems, Volume 66, August 2014, Pages 146-155
[10]Bin Gu, Victor S. Sheng. Feasibility and Finite Convergence Analysis for Accurate On-line ν-Support Vector Learning. IEEE Transactions on Neural Networks and Learning Systems, 24(8):1304-1315, 2013.
[9]Bin Gu, Jian-Dong Wang, Guan-Sheng Zheng, Yue-Cheng Yu. Regularization Path for ν-Support Vector Classification. IEEE Transactions on Neural Networks and Learning Systems, 23(5): 800-811,2012.
[8]Bin Gu, Jian-Dong Wang, Yue-Cheng Yu, Guan-Sheng Zheng, Yu-Fan Huang, and Tao Xu. Accurate on-line ν-support vector learning. Neural Networks, 27(0):51–59, 2012.
[7]Bin Gu, Guan-Sheng Zheng, Jian-Dong Wang. Analysis for Incremental and Decremental Standard Support Vector Machine. Journal of Software, 24(7):1601-1613, 2013. (In Chinese)
[6]Bin Gu, Jian-Dong Wang. Effective ν-Path Algorithm for ν-Support Vector Regression. Journal of Software, 23(10): 2643−2654,2012. (In Chinese)
[5]Bin Gu, Jian-Dong Wang, and Tao Li. Ordinal-Class Core Vector Machine,Journal of Computer Science and Technology. 2010, 25(4): 699-708.
[4]Bin Gu, Jian-Dong Wang, and Hai-yan Chen. On-line Off-line Ranking Support Vector Machine and Analysis. In Proceedings of International Joint Conference on Neural Networks (IJCNN’08), New York: IEEE Press, 2008.
[3]Bin Gu, Jian-Dong Wang. A Novel Feature Extraction Method for QAR Data. Journal of Sichuan University: Engineering Science Edition, 2011, 3(43):113-117. (In Chinese)
[2]Bin Gu, Jian-Dong Wang.A Class of Methods for Calculating the Threshold of Local Outlier Factor.Journal of Chinese Computer Systems,2008,29 (12):2254-2257. (In Chinese)
[1]Tao Xu, Jian_Li Ding, Bin Gu, Jian-Dong Wang. Forecasting Warning Level of Flight Delays Based on Incremental Ranking Support Vector Machine. Acta Aeronautica et Astronautica Sinica,2009,30(7): 1256-1263. (in Chinese)
员工培养:
人工智能的发展之一是让计算机模拟人的经验学习能力。机器学习主要研究经验学习使得机器具备经验学习能力。目前机器学习尤其是大模型在产业界得到空前的应用。我们组主要侧重对机器学习中主流算法进行理论研究,以及产业化应用。
实验室目前招收本科实习生、硕士以及博士生,欢迎对机器学习有兴趣的员工与我联系。适合本实验室的员工应具备的基本特征如下:
1.品行端正,诚实守信
2.对机器学习,人工智能有兴趣
3.能吃得了苦,坐得了板凳
注:编程、数学、英语能力好是加分项,不是必需项。我们在培养过程中充分利用员工的优势,挖掘员工的潜力,助力员工全面成长


